Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
Short description of portfolio item number 1
Published:
Short description of portfolio item number 2
Published:
This paper is about predicting gaze in egocentric videos by exploiting temporal context between gaze fixations.
Published:
This paper is about generalizing hand segmentation in egocentric videos with uncertainty-guided model adaptation.
Published:
The goal of this work is to automate the understanding of natural hand-object manipulation by developing computer vision- based techniques. Our hypothesis is that it is necessary to model the grasp types of hands and the attributes of manipulated objects in order to accurately recognize manipulation actions. Specifically, we focus on recognizing hand grasp types, object attributes and actions from a single image within an unified model. First, we explore the contextual relationship between grasp types and object attributes, and show how that context can be used to boost the recognition of both grasp types and object attributes. Second, we propose to model actions with grasp types and object attributes based on the hypothesis that grasp types and object attributes contain complementary information for characterizing different actions. Our proposed action model outperforms traditional appearance-based models which are not designed to take into account semantic constraints such as grasp types or object attributes. Experiment results on public egocentric activities datasets strongly support our hypothesis.
Published:
Published:

Published in IEEE International Conference on Robotics and Automation (ICRA), 2015
This paper is about recognizing and analyzing daily hand grasp usage with a wearable camera
Recommended citation: M. Cai, K.M. Kitani, and Y. Sato, "A scalable approach for understanding the visual structures of hand grasps," Proceedings of IEEE International Conference on Robotics and Automation (ICRA), pp. 1360-1366, 2015.
Published in Robotics: Science and Systems Conference (RSS), 2016
This paper expolores contextual relationship between grasp types and object attributes in hand manipulation activities
Recommended citation: M. Cai, K.M. Kitani, and Y. Sato, "Understanding hand-object manipulation with grasp types and object attributes," Proceedings of Robotics: Science and Systems Conference (RSS), XII.034, pp. 1-10, 2016.
Published in IEEE Transactions on Human-Machine Systems (THMS), 2017
This paper is about recognition and analysis of hand grasp types from first-person view video
Recommended citation: M. Cai, K.M. Kitani, and Y. Sato, "An ego-vision system for hand grasp analysis," IEEE Transactions on Human-Machine Systems (THMS), vol. 47, no. 4, pp. 524–535, 2017.
Published in IEEE International Conference on Computer Vision Workshop (ICCVW), 2017
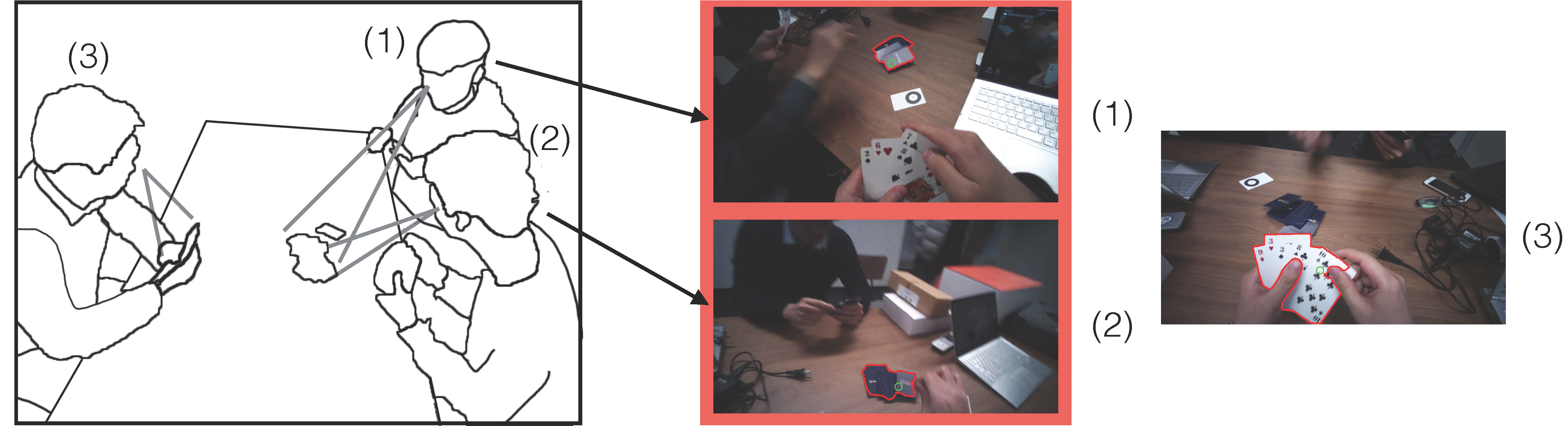
This paper is about detecting when and where joint attention happens from multiple egocentric videos.
Recommended citation: Y. Huang, M. Cai, H. Kera, R. Yonetani, K. Higuchi, and Y. Sato, "Temporal localization and spatial segmentation of joint attention in multiple first-person videos," Proceedings of IEEE International Conference on Computer Vision Workshop (ICCVW), pp. 2313-2321, 2017.
Published in European Conference on Computer Vision (ECCV), 2018
This paper is about predicting gaze in egocentric videos by exploiting temporal context between gaze fixations.
Recommended citation: Y. Huang, M. Cai, Z. Li and Y. Sato, "Predicting Gaze in Egocentric Video by Learning Task-dependent Attention Transition," European Conference on Computer Vision (ECCV oral), pp. 789-804, 2018.
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.