
Understanding hand-object manipulation with grasp types and object attributes
Published in Robotics: Science and Systems Conference (RSS), 2016
Recommended citation: M. Cai, K.M. Kitani, and Y. Sato, "Understanding hand-object manipulation with grasp types and object attributes," Proceedings of Robotics: Science and Systems Conference (RSS), XII.034, pp. 1-10, 2016.
Abstract
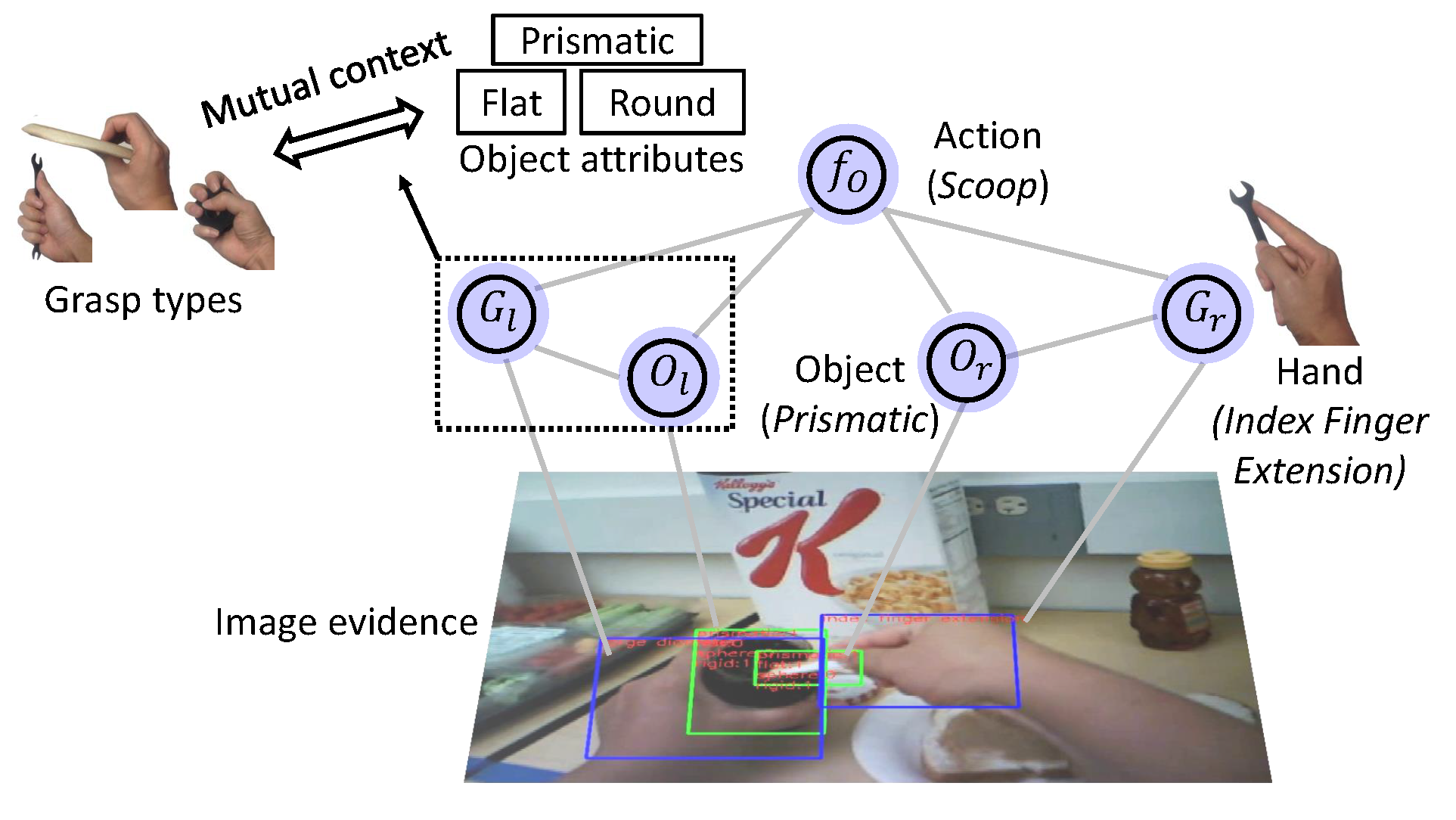
The goal of this work is to automate the understanding of natural hand-object manipulation by developing computer vision- based techniques. Our hypothesis is that it is necessary to model the grasp types of hands and the attributes of manipulated objects in order to accurately recognize manipulation actions. Specifically, we focus on recognizing hand grasp types, object attributes and actions from a single image within an unified model. First, we explore the contextual relationship between grasp types and object attributes, and show how that context can be used to boost the recognition of both grasp types and object attributes. Second, we propose to model actions with grasp types and object attributes based on the hypothesis that grasp types and object attributes contain complementary information for characterizing different actions. Our proposed action model outperforms traditional appearance-based models which are not designed to take into account semantic constraints such as grasp types or object attributes. Experiment results on public egocentric activities datasets strongly support our hypothesis.
[Paper] [Code]